An Ode To Build a Database

After a looong hiatus, I finally got back to using C. Definitely slightly rusty but I'm able to recollect the concepts and syntax. As usual, pointers are a pain in the neck; can't avoid them, though.
I thought of resharpening my C by taking on a project → to build a database from scratch. I started reading a few resources (linked down below) about the different components of a database and variaous inner mechanisms.
Databases Decoded
A database consists of many smaller parts that work in tandem by taking in a query and adding it to a table while ensuring there's no memory leak anywhere. A user-facing database has two sides – the interface and the backend. The query passes through the two layers before finally sitting atop the computer's disk.
User-facing REPL
The user-facing side of the database deals purely with breaking down queries into smaller parts (or tokens) that will soon be dumped into the table by the backend.
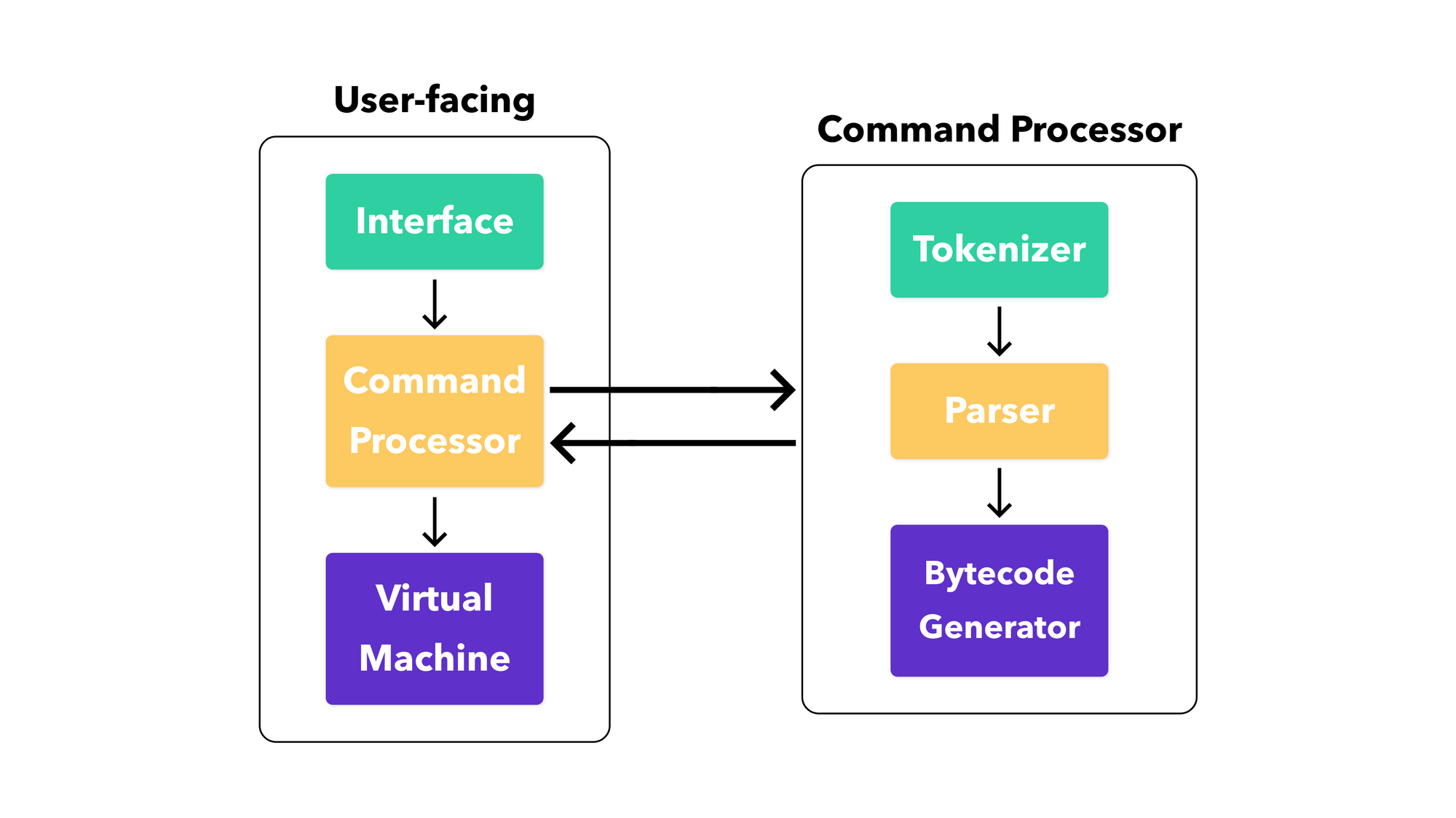
To put things into context, the interface is the familiar prompt you see when you log into a sqlite (or mysql) session in the terminal:
sqlite>It receives the queries from the user and passes it down to the Command Processor which breaks down the query statement into tokens. These tokens must conform to the schema you've used for the table.
Suppose we have the following query:
sqlite> insert into Users values (1, John, jdoe@gmail.com); Tokens refer to the terms that come after the insert into Users values part → the values being put into the table. The Command Processor deciphers the terms one by one and checks that they all belong to the correct table attribute in the right order, assuming the table followed a simple ID, Name, Email schema.
Once the checks are completed, the query is translated into bytecode, a low-level representation of the query and its data, for the virtual machine that's running under the hood. The virtual machine then runs this bytecode which interfaces with the underlying backend mechanism.
Backend
The backend consists of modules that manipulate the data structures used by the database. The most commonly-used data structure is the B-tree, a self-balancing tree structure that maintains sorted data and allows common database operations like insertion, search, update, and deletion.
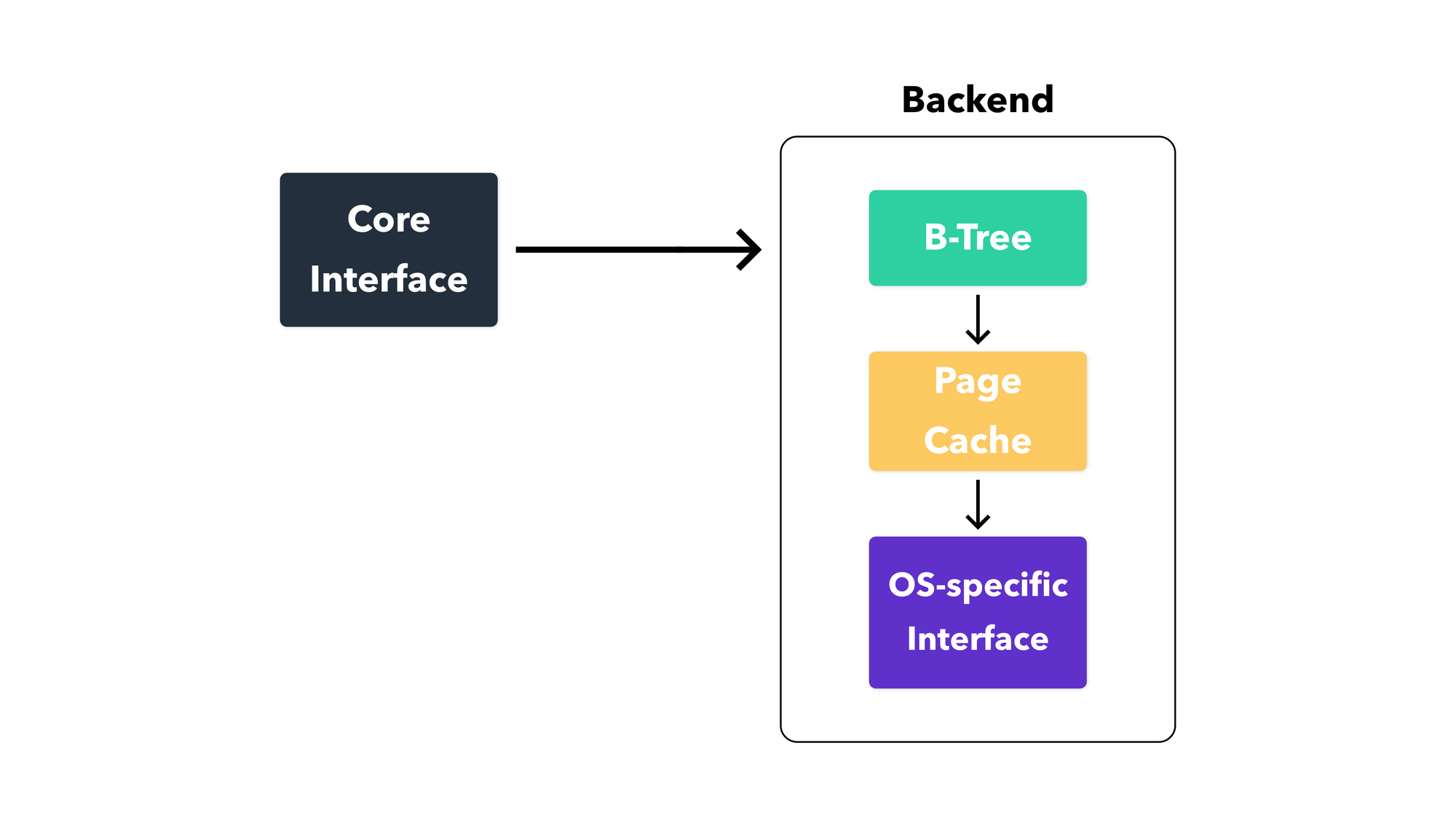
Each table has its separate B-Tree to index the data being stored. The B-Trees are all found on the computer's disk.
For more information on how data is stored on computer disks, read my other article:
How Does Computer Storage Work?
Indexing Large Databases
Suppose we have the following schema for a database.
UID→ 16 bytesname→ 32 bytesemail→ 80 bytes
If we have 100 records in database each with their own primary key UID, each record will take up 128 bytes of space. In total, we're using 12800 bytes on the system. To store all of them on the disk, we need 25 blocks each holding 4 records (assuming each block holds 512 bytes).
Now, if I shoot a query at the database, the database needs to search 25 blocks choke-full of data, which is a horrible, time-consuming process.
To fix this, we need to have a database for our database. This is called an Index. The index contains the same number of records as the database (100 records) but occupies lesser space.
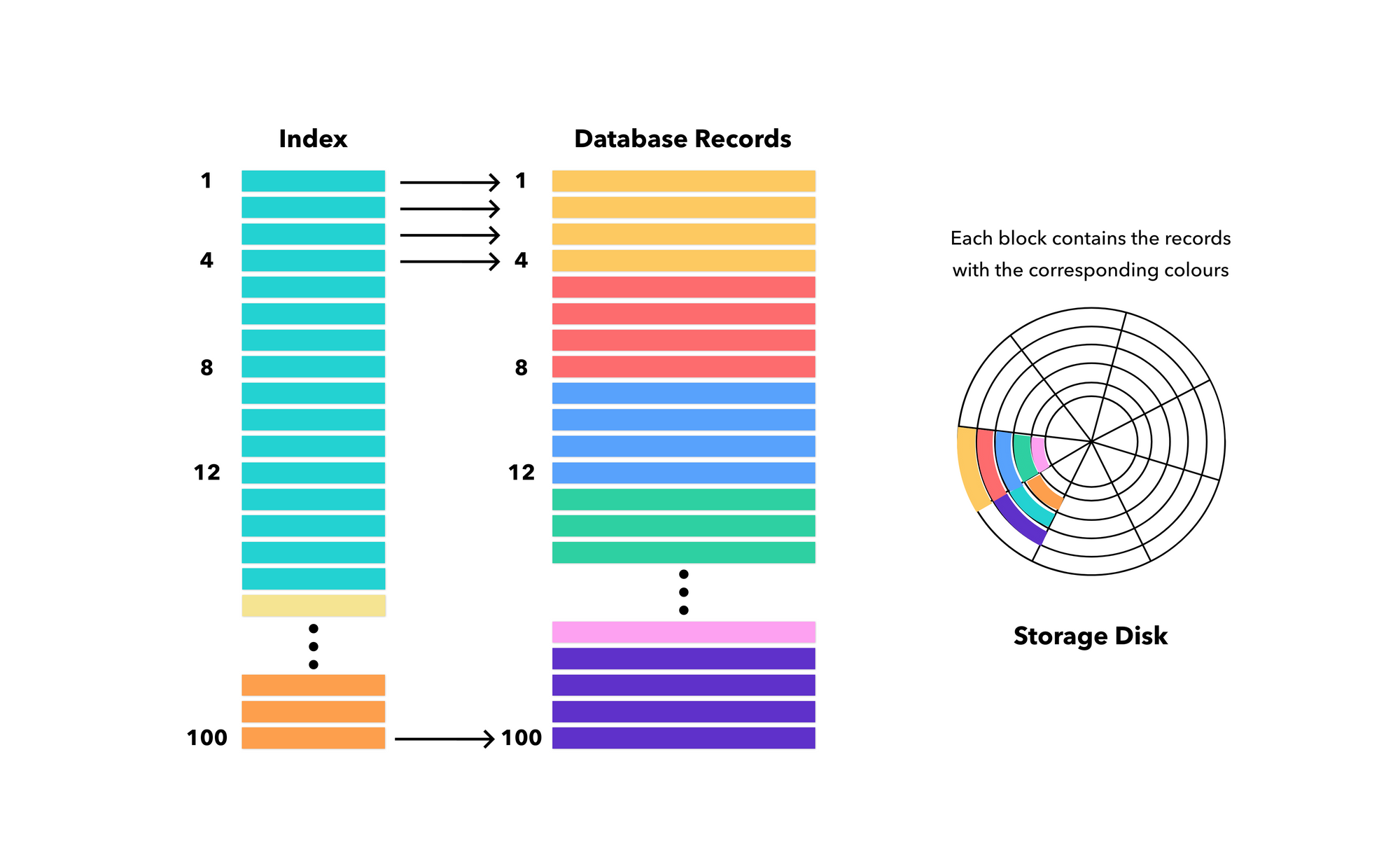
Each index record contains UID and a pointer to the associated record in the database. Say the pointer takes up 16 bytes as well. In total, the index record occupies 32 bytes of space. In toal, the index occupies 3200 bytes. This means, the entire index, at max, would take up roughly 7 blocks on the disk, each carrying 16 index records each.
Ultimately, this leaves us with blocks doing two things → one holding the database records and another holding the index records.
When a search query for a particular record is made, here's what we do:
Search the
7index blocks forUIDWhen
UIDis found in the index blocks, access the associated pointerAccess the database block containing the record connected to the pointer
Search for
UIDin the the block to find the record
So, if we zoom out, we searched through 7 + 1 blocks in total to find the target record. If we did not use an index, we'd have to search 25 blocks instead. Note that we aren't searching the database at all. In a sense, we are only searching the blocks to find the record.
Now, imagine you have 100000 record in your database. As such, your index increases in size as well, making search a time-consuming process. To fix this, we create another index for the index, where each record contains UID and a pointer to the index record instead of the database block that contains the record. If this index becomes too large, create a third index, and so on.
This process of using many indexes to decrease the search time is called Multi-level Indexing.
The OS interface refers to the OS-specific upgrades given to the database software to help it run smoothly. Using abstract objects, files can be opened, read, updated, and closed on disk. Some schemas have DATETIME attributes in them → the OS interface is responsible for accessing such information and relaying it up the ladder for the user to query. It's also used to randomly identify and tag each record that's put into the system.
After going through the backend, the inserted data is persistent and will only be irrecoverable if the data in the table is deleted or the disk is corrupted/damaged.
Building Discount SQLite in C
Over the past week, I read flipped through quite a few online resources about database processes and construction. I made the unorthodox choice of giving C another go after nearly 8 years and so far it has been a smooth ride, bar pointers.
Thus began the creative journey behind NachoDB 🧀 Do not ask me why I chose that name. I had a bag of Doritos lying next to me when I was searching for interesting names.
To recreate the bare minimum functionality of SQLite, the following had to be programmed:
A query buffer to take in statements from the user. I kept it simple →
insert,select,delete, andexitA compiler that breaks down a query into its component tokens and translates them to bytecode
A B-Tree to create, search, and update pages, with each page taking up
4096bytesA page cache that stores machine level data; this interacts with the B-Tree and passes it pages
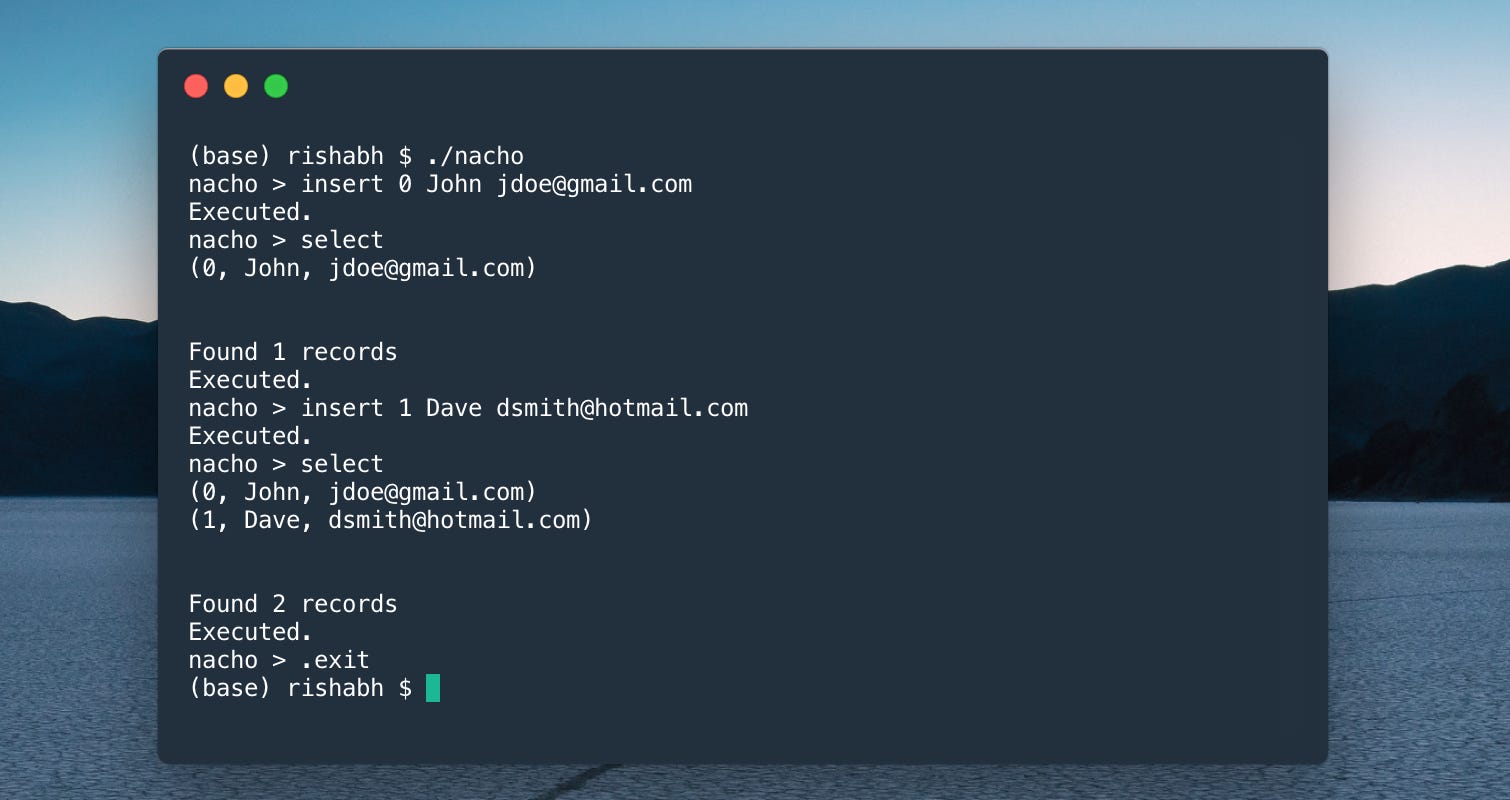
That's about it! This was a super cool project to undertake and I learned a lot about databases. You can find my code here:
It's fully written in C so I'd suggest familiarising yourself with the syntax before going down a rabbit hole you can't escape 😅
Database Resources
As promised up top, here are some really cool articles on databases I came across. They talk about different components of database design and creation from the ground up.